Abstract
Synthesized speech from articulatory movements can have real-world use for patients with vocal cord disorders, situations requiring silent speech, or in high-noise environments. In this work, we present EMA2S, an end-to-end multimodal articulatory-to-speech system that directly converts articulatory movements to speech signals. We use a neural-network-based vocoder combined with multimodal joint-training, incorporating spectrogram, mel-spectrogram, and deep features. The experimental results confirm that the multimodal approach of EMA2S outperforms the baseline system in terms of both objective evaluation and subjective evaluation metrics. Moreover, the results demonstrate that joint mel-spectrogram and deep feature loss training can effectively improve system performance.
Motivation
Silent speech interfaces enable people to communicate without the presence of an acoustic signal. Such techniques can provide patients who suffer from vocal cord disorders a more natural alternative way to communicate. Also, these techniques can be helpful in situations requiring acoustic silence, or in high-noise environments, since acoustic signals are not required as input and thus background noises have a greatly reduced effect.
Proposed EMA2S
The following is the proposed EMA2S, which integrates the idea of multimodal training and the deep feature loss.
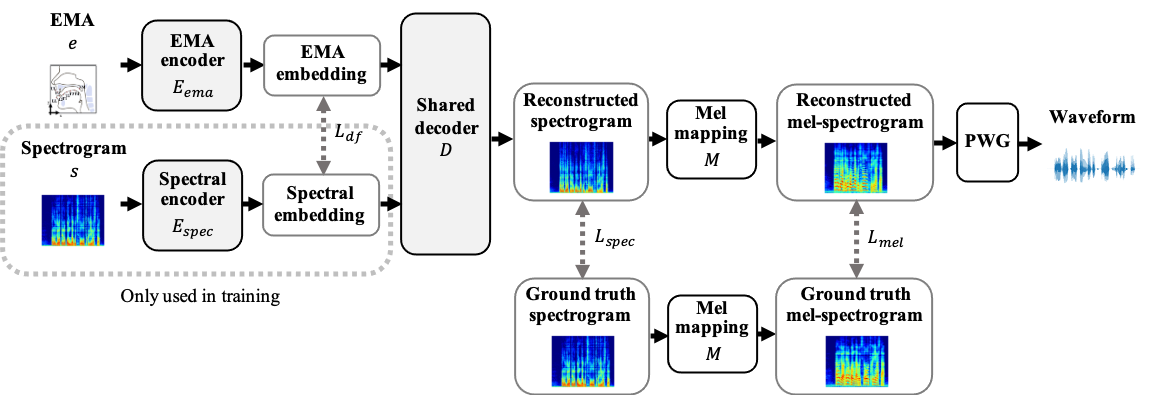
See Paper for more detail.