A Study of Incorporating Articulatory Movement Information in Speech Enhancement
Proc. EUSIPCO 2021
Posted on November 4, 2021
Abstract
Although deep learning algorithms are widely used for improving speech enhancement (SE) performance, the performance remains limited under highly challenging conditions, such as unseen noise or noise signals having low signal-to-noise ratios (SNRs). This study provides a pilot investigation on a novel multimodal audio-articulatory-movement SE (AAMSE) model to enhance SE performance under such challenging conditions. Articulatory movement features and acoustic signals were used as inputs to waveform-mapping-based and spectral-mapping-based SE systems with three fusion strategies. In addition, an ablation study was conducted to evaluate SE performance using a limited number of articulatory movement sensors. Experimental results confirm that, by combining the modalities, the AAMSE model notably improves the SE performance in terms of speech quality and intelligibility, as compared to conventional audio-only SE baselines.
Motivation
The speech enhancement (SE) performance decreases drastically when encountering unknown noises or very low signal-to-noise ratio (SNR) conditions. Therefore, we proposed to incorporate articulatory movements, which are robust to environmental changes, in speech enhancement. <\br >
Introduction to Articulatory Movement Data
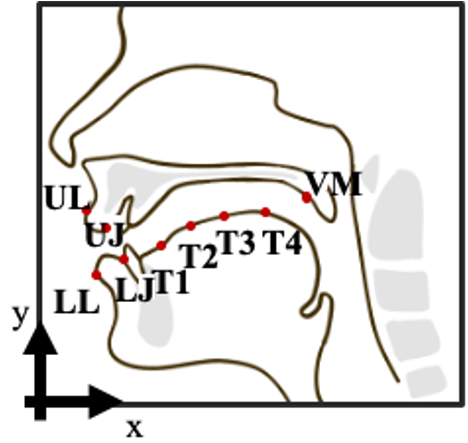
In this study, we used articulatory movement data collected by Electromagnetic Midsagittal Articulography (EMA or EMMA).
To collect EMMA data, you need to put sensors inside your mouth; then, the machine will record the movement of your vocal tracts. The position of EMMA sensors are as follows:
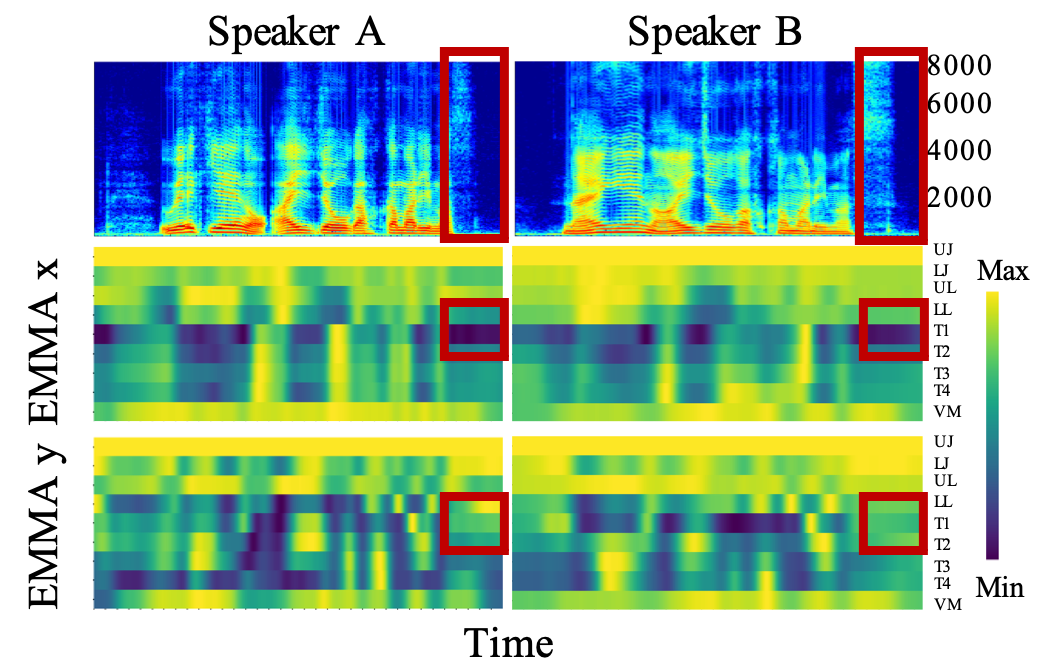
The following figure shows the speech spectrograms and the EMMA signals of two speakers speaking the same utterance. Both the spectrograms and EMMA signals display similar patterns, indicating that these resultant signals are highly dependent on the pronunciation.
Visualization of the EMMA data. Red box indicates speakers pronouncing /s/.
In recent years, numerous in-mouth sensors, such as smart palate systems, smart dental braces, and in-mouth monitoring have been developed to collect articulatory features. Therefore, we are certain that in-mouth sensors will have increased practical usage in the future, and the results of this study can be applied to articulatory movements collected from various devices.